Monitoring of Database Queries
- Andre van Hoorn
- Dominic Parga Cacheiro
0 Open questions
Chapter 2.2
What does "vendor specific calls on the client API" mean? For me, vendor means something like "someone who sells something".
Chapter 5
Chapter 8.1
The question is described in the chapter summary below.
Open tasks:
- It says "In our thesis, we use the IRL to define compatible Kieker records for the integration into Kieker Trace Diagnosis."
=> Maybe here are some code examples
Instrumentation Record Language:
http://www.oiloftrop.de/code-research/instrumentation-record-language/
https://github.com/kieker-monitoring/instrumentation-languages
1 Introduction
1.2 Goals
- "The main goal of our thesis is to design and implement a performance monitoring tool for database operations." (p. 2)
- The paper does NOT handle the detection of performance problems. It is used only for "Monitoring of Database Operations" and afterwards "Trace Diagnosis" (p. 2).
- The paper uses Kieker and ExplorViz to verify the goal.
2 Foundations and Technologies
2.1 Foundations
2.1.1 Dynamic Analysis
This technique "comprises the process of analyzing a running program with focus to its deriving properties, which are valid at least for one or more executions of a program [Ball 1999]." (p. 5) For me, this means analyzing a software by executing it repeatedly and validating its input/output parameters. An advantage: It is possible to detect unused code (= dead code).
2.1.2 Reverse Engineering
This technique contains quite everything what you would expect; it is the reverse of normal software development: "analysing a subject system to (i) identify its current component and their dependencies and (ii) to extract and create system abstractions and design information" (p. 5). It is used to understand the analized software better. This makes performance improvements possible.
2.1.3 Performance Analysis
Important definition: Performance Analysis serves understanding AND predicting the time dependent behaviour of a software.
2.1.4 Aspect-Oriented Programming
Short form is AOP. This technique is used to seperate the original code from the monitoring code including instrumentation code and probes. "This process is handled through weaving the monitoring code into the source code." (p. 7)
2.1.5 Usability Testing
Not much explained, what I prefer because for me, there is not a lot to say about usability in general. You have to guarantee, that users of your software enjoy working with it and producing expected content without unnecessary complications. Therefore, the paper defines it as a "description of the ease of use and learnability of the developed software applications" (not word by word from p. 8)
2.1.6 Usability Testing
User-centered design => direct feedback from users
2.1.7 Usability and User Experience Questionnaires
You have to test usability by asking the users. Asking them effectively assumes you having to think about your questions accordingly carefully. "One of the most popular web questionnaires is the System Usability Scale (SUS), as it is a quick and validated test." (p. 9)
2.2 Technologies ans Tools
2.2.1 JDBC
All quotes are from p. 9.
JDBC = Java Database Connectivity: "Java API for database-independent communication between Java and several databases." The JDBC library offers e.g. handling database connections including:
- defining and executing SQL statements
- delivering and displaying result sets
Using JDBC involves a JDBC driver. It "enables a Java application to interact with a manufacturer-specific database. A driver is assigned to one of four categories":
- JDBC-ODBC Bridge Driver
- Partial JDBC Driver (most commonly used)
- Transforms the JDBC calls into vendor specific calls on the client API (DB ClientLib) like Oracle or DB2
- Network-Protocol Driver (also known as the MiddleWare Driver) (most commonly used)
- Converts the JDBC calls into the middleware protocol
- The middleware translates it to a vendor specific DBMS protocol
- Database-Protocol Driver (Pure Java Driver)
2.2.2 AspectJ
AspectJ is an extension for Java and bases on the idea of AOP. There are three types of weaving:
- Compile-Time-Weaving: class files including aspects
- Binary-Weaving: if source files are not available
- Load-Time-Weaving: modifies the Binary-Weaving; weaving only when JVM is applied
2.2.3 Kieker Monitoring Framework
"It collects and analyzes monitoring data on different abstraction levels. Furthermore, it measures operation response times and traces using dependency graphs [Hasselbring 2011] of a software run [van Hoorn et al. 2009; 2012]." (p. 11)
Important basic concept: Kieker.Monitoring is seperated from Kieker.Analysis. Between them, the monitored data is saved as Monitoring Records. Furthermore, "it also provides for previously analyzed monitoring data several visualizations, such as Unified Modeling Language (UML) sequence diagrams and dependency graphs." (p. 11)
2.2.4 Instrumentation Record Language (IRL)
This is a language to generate data structures and serialization code for C, Perl and Java. It is also integrated well as an plug-in into the Eclipse editor.
2.2.5 TeeTime
Pipe-and-Filter Framework for Java; used for the analysis of their generated monitoring logs
2.2.7 Kieker Trace Diagnosis
"Kieker Trace Diagnosis is an additional tool for further analysis and visualization purposes within the Kieker Monitoring Framework. As it is still under development, it has not been released yet." (p. 12)
2.2.8 ExplorViz
All quotes are from p. 13.
- "Live trace visualization tool for large software landscapes [Fittkau et al. 2013b]"
- Uses dynamic analysis techniques
- Two different visualization perspectives:
- landscape: "employes a notation similar to the UML"; provides overview
- application level: 3D software city metaphor
3 Approach for Database Monitoring
Architecture of the software system:
The existing software contains the Monitored Application accessing the Database using JDBC. To monitor this application, an approach is used containing a the Monitoring Component (using AOP to create monitoring logs) and the Trace Diagnosis (analyzing and visualizing the monitoring logs).
4 Monitoring of Database Operations
4.1 Related SQL Relationships
"Basically 3 options to define and execute a statement, respectively a query, within JDBC": (p. 17)
- Statement
Standard SQL statement - PreparedStatement
Extends Statements "with the purpose to set-up an abstract SQL-statement with parameters in order to precompile it." (p. 17)
=> improvement of the execution time - CallableStatement
Extends PreparedStatements by allowing executing "Stored Procedures, which are developed functions that are stored within the database. These are capable to handle multiple results."
The paper's focus lays on Statements and PreparedStatements, because they are the most commonly used database operations.
4.2 Generic Monitoring Approach
4.2.1 Choosing an Instrumentation Technique
- Java Proxy
A method is invoked on the proxy => a registered invocation handler is being notified about:- which method has been executed
- calling parameters
- on which object is the method called
- cglib
Byte code instrumentation library to generate and transform Java byte code - Javaassist (short version for Java programming assistant)
Another byte code manipulating library. Allows defining new classes at runtime and modifying class files, when loaded by the JVM.
4.2.2 Concrete Instrumentation Approach
The Monitoring components as a pipeline:
[ [Monitoring Probe] - ( - - Logging - - > O - [Monitoring Controller] - ( - - Logging - - > O - [Monitoring Writer] - ( - - ] - - > [Monitoring Records]
Structure of monitoring records (quoted from p. 22, concrete description on page 41 in chapter 8.2):
- record type: differs between before or after event
- timestamp: represents date and time of the record
- operation name: full Java class name
- return type: e.g., ResultSet, boolean or int
- return value: e.g., number of affected database records
- operation arguments: e.g., SQL statement
Exportable to Kieker record structure
5 Analysis of Database Records
Analyzing, processing and preparing recorded monitoring data for the later described visualization. I haven't understood everything in this chapter. It says how you analyze database records using a "Generic Monitoring Record Processing" (Figure 5.1. at page 24). This process uses a Log Reader for reading in the records, that provides it for the Record Filter. "The Record Filter analyzes and matches a monitoring record type, e.g., a before or after event record (entering or leaving a database operation), and creates a related database record object" (p. 24). The Record Transformator transforms the created record object into a database operation call object. The Record Merger merges two record objects into one record. This is needed because "we have basically two record types, before and after event, for a single executed database operation" (p. 24).
What I don't understand: What is the difference between the Record Transformator and the Record Merger? I don't understand the difference between a "database operation call object" (= output of the Record Filter) and the output of the Record Merger.
Rest of the chapter is about distributing/serving the data for analysis.
6 Visualization of Database Records
6.1 Different View Options
6.1.1 Dependency Graphs
"Based on the hierarchy of a call, these graphs can be constructed and enriched with other metrics, e.g., response times, to support tasks like conducting a performance analysis." But because their "monitored database operations have a flat hierarchy", they "would have a bulk of dependency graphs." (p. 27)
6.1.3 Call Tree Views
= List of calls containing calls. This has the advantage to calculate needed times, number of calls, percentages of them, etc. per call. You are able to go deeper in the tree to focus a special called more detailled.
In the case of the paper, a call is a database statement. Call Tree Views are used in Kieker Trace Analysis, so the statements are implemented as some kind of call.
Different representations:
- Statements: "including the executed SQL statement and the response time"
- Aggregated Statements: "same as Statements, but aggregated based on their executed SQL statement."
=> I would say, this means: Choosing statements out of a set of many executions of one statement. It is used for analyzing one statement independant of one statement call. - Prepared Statements: "providing the abstract prepared statement and the concrete execution with bound parameters."
=> Choosing parameter values per statement
7 Overview of our Implementation
Design goal: as light-weight and generic as possible, in order to allow multiple analysis and visualization tools using the recorded monitoring data as input
7.1 Architecture
7.1.1 Monitoring Component
The architecture of the implementation:
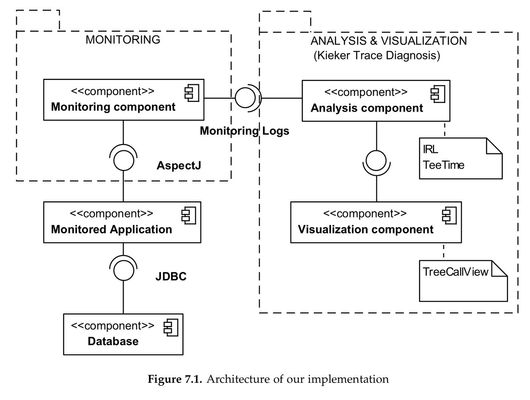
"The Monitoring component needs to be located within the execution container or environment of the application, as our instrumentation is woven into the program code by a Java agent." (p. 34) Furthermore, it is shown in the figure above, that the monitoring component is fully independant by the analysis and visualization components. They could execute on seperated machines using the monitoring logs.
7.1.2 Analysis Component
The visualization component is just depending on the records created by the analysis component. So it should be possible to create a serializable record type to seperate the visualization component from the analysis like the (analyis & visualization) component from the monitoring component. It would be possible to create many different visualizations on the same records.
7.1.3 Visualization Component
The visualization bases on a MVC (Model-View-Controller) architecture within Kieker Trace Diagnosis using Tree Call Views. Furthermore, "capabilities to filter and sort the recorded data, in order to support the user in conducting a performance analysis on database operations" (p. 35) are provided.
8 Monitoring Implementation
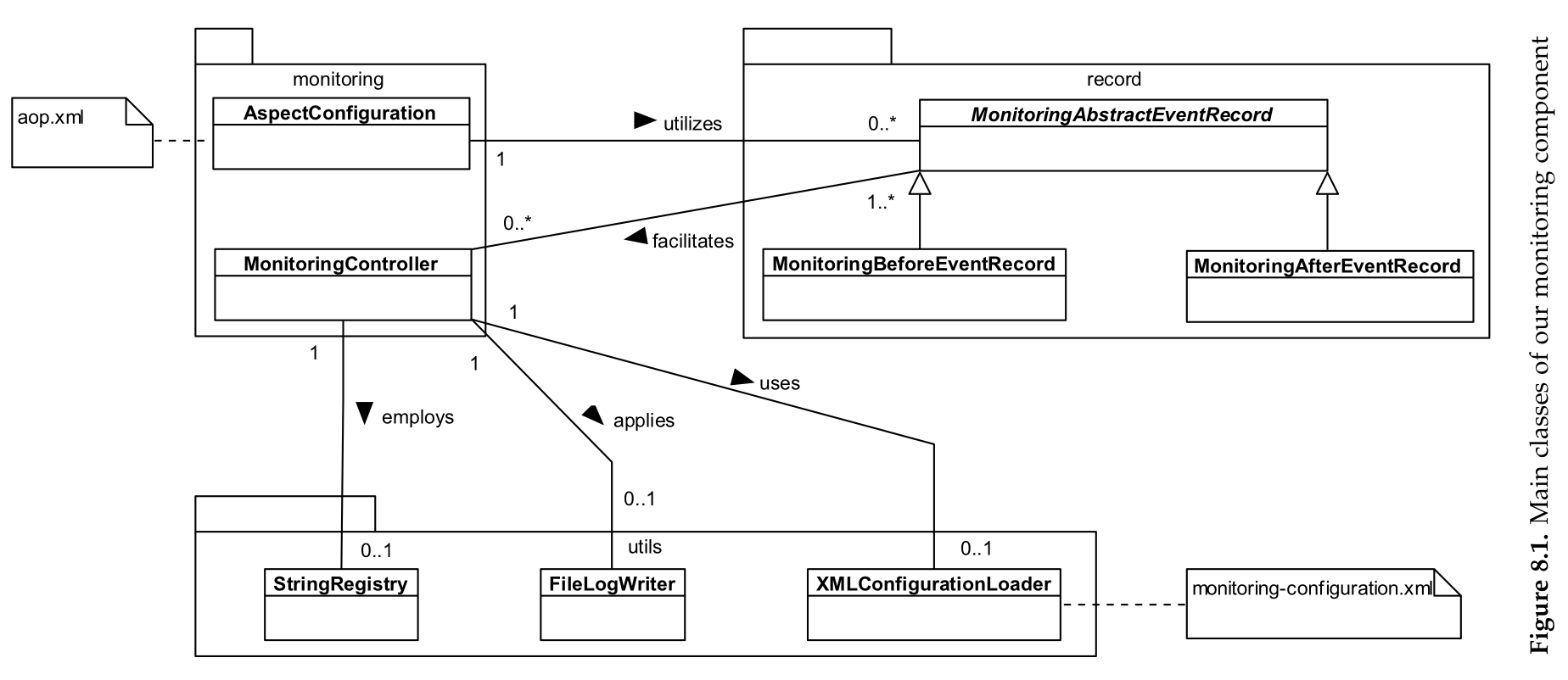
Infos:
- aop.xml and monitoring-configuration.xml are configuration files "to configure the instrumentation process dynamically, without the need to change the source code." (p. 37)
- "The monitoring package includes all necessary classes for the instrumentation through AspectJ." (p. 37)
8.1 Instrumentation Utilizing AspectJ
The monitoring-configuration.xml serves some basic functionality, e.g. toggling the monitoring or the debug mode on/off. The MonitoringController uses default values, if there are invalid configuration settings. The AspectConfiguration uses around advices for the database pointcuts and "creates a corresponding monitoring record." (p. 40)
In the paper on page 40, it says "Additionally, we have to distinguish between database operation calls, which are created when an operation has started on the one side, and when it is completed on the other side." This sounds like one database call includes 2 calls. If yes, why are around advices used instead of before and after advices?
The following figure shows the used aop.xml. This is needed by AspectJ.

It is known, that the all java software systems are weaved, not only the needed database system(s). The paper says, loading "classes of a concrete observed Java software system (...) did not work properly" (p. 40).
8.2 Monitoring Record Processing
For further processing of the created monitoring records, the class MonitoringAbstractEventRecord is utilized by using "its concrete derivatives MonitoringBeforeEventRecord and MonitoringAfterEventRecord.
The "previously mentioned monitoring record attributes [chapter 4.2.2; added by Dominic Parga Cacheiro] (...) are listed in the following:" (quoted from p. 41)
- cid: an unique identifier for mapping before and after event records
- classNameId: mapped id, which represents the full Java class operation name
- classArgsId: mapped id, which represents the operation argument, e.g., a SQL statement
- timestamp: represents date and time of the record
- return value's type: parsed from the full class name [added by Dominic Parga Cacheiro]
- formattedReturnValue: returned value of an executed operation, formatted based on the returned data type of the operation
- record type: handled through its derivate classes MonitoringBeforeEventRecord and MonitoringAfterEventRecord [added by Dominic Parga Cacheiro]
The id's are used combined with a string in the StringRegistry in the package utils. This "operates like a mapper between strings and an id." (combination of p. 40 and p. 41). It explains the usage with "employ[ing; changed by Dominic Parga Cacheiro] this technique to improve [the; changed by Dominic Parga Cacheiro] monitoring speed, as multiple class operation names or arguments are just added once to the registry." (p. 41)
8.3 File Writing
Monitoring records are sequentially written to the file system using the FileLogWriter.

"Each line represents a monitoring record and the inherited logging attributes are separated by a semicolon. The leading value indicates the type of monitoring record ($0: MonitoringBeforeEventRecord and $1: MonitoringAfterEventRecord)." (p. 42)
In addition: "As Kieker needs to know, which exact record type is represented in the log file for the analysis, a mapping file, namely kieker.map, needs to be specified." (p. 43) IRL "record classes are defined in this file for a correct mapping." (p. 43)
$0=kieker.common.record.io.database.DatabaseBeforeEventRecord
$1=kieker.common.record.io.database.DatabaseAfterEventRecord
9 Analysis Implementation
This picture is out of p. 45 and is explained in the including text out of the paper.
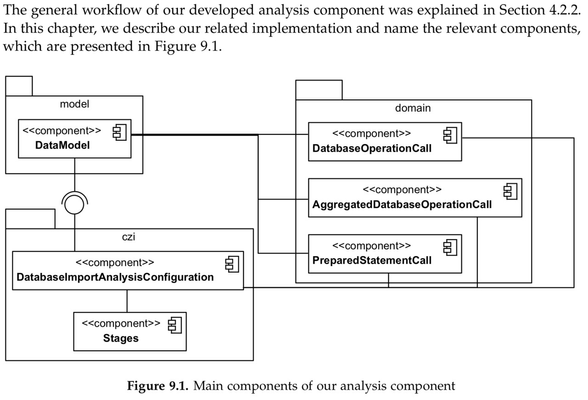
- DataModel acts as a data storage for kieker Trace Diagnosis
- "The package domain contains mapping classes for our previously generated monitoring records." (p. 45)
9.1 Monitoring Record Classes
These classes use records as base and extend AbstractOperationCall, as it already provides useful attributes (e.g. component, operation, the option to define children objects). By this, you can construct trees.
9.1.1 DatabaseOperationCall
The title is the name of the primary class for storing and processing monitored database operation calls. This class contains the following attributes (quoted from p. 46f):
- traceid: an unique identifier for statements
- duration: the duration of the executed statement
- timestamp: represents date and time of the record
- callArguments: includes the executed SQL statement
- returnValue: returned value of an executed operation, formatted based on the data type
- parent: contains a reference to a parent object, if one exists
9.1.2 AggregatedDatabaseOperationCall
This class "is applied as a data structure for aggregated statements based on their executed SQL statement." (p. 47) This class contains the following attributes (quoted from p. 47):
- totalDuration: the total used response time, regarding a specific aggregated statement
- minDuration: the minimum duration of the executed statement
- maxDuration: the maximum duration of the executed statement
- avgDuration: the average duration of the executed statement
- calls: the number of calls or children of a specific aggregated statement
- callArguments: includes the executed SQL statement
- parent: contains a reference to a parent object, if one exists
"For each SQL statement a parent call is created. If a parent call for a statement call already exists, then the statement call is added as a child to the parent call."
9.1.3 PreparedStatementCall
This is used for prepared statements (see chapter 4). This class contains the following attributes (quoted from p. 48):
- traceID: an unique identifier for a prepared statement
- duration: the duration of the execution
- timestamp: represents date and time of the record
- abstractStatement: includes the precompiled SQL statement, only if the object is a parent object
- concreteStatement: shows the concrete executed SQL statement, only if the object is not a parent object
- returnValue: returned value of an executed operation, formatted based on the data type
- parent: contains a reference to a parent object, if one exists
"Each abstract statement defines its own call tree hierarchy. The abstract statement object embodies the parent element and the concrete statements are referenced children nodes."
9.2 DataModel
"This is a central container for data, which is used within the application." (p. 49; little changes by Dominic Parga Cacheiro) It offers data structures for the analysis and necessary information for the visualization. Attributes out of a reduced class diagram follows (containing commenty by Dominic Parga Cacheiro):
// "lists for storing the results from the analysis for the database calls" (p. 49)
-databaseOperationCalls : List<DatabaseOperationCall>
-databaseStatementCalls : List<DatabaseOperationCall>
-aggregatedDatabaseStatementCalls : List<AggregatedDatabaseOperationCall>
-databasePreparedStatementCalls : List<PreparedStatementCall>
// location of monitoring log
-importDirectory : File
// timestamps
-timeUnit : TimeUnit
-beginTimestamp : long
-endTimestamp : long
9.3 Analysis Configuration